
Request access to Gemma-2-9b-it model.
#55
by index931 - opened

I requested permission, but it still shows as pending. Could you please grant me permission to use Google's Gemma models family?
index931 changed discussion title from Request access to Google’s Gemma-2-9b-it model. to Request access to Gemma-2-9b-it model.


Hi @index931 ,
Follow the link provided below and complete the steps to gain access to the “Google Gemma models on HuggingFace”.
https://www.kaggle.com/models/google/gemma-2/license/consent
Click on “Verify via Hugging Face” and also click “continue with Hugging Face”.
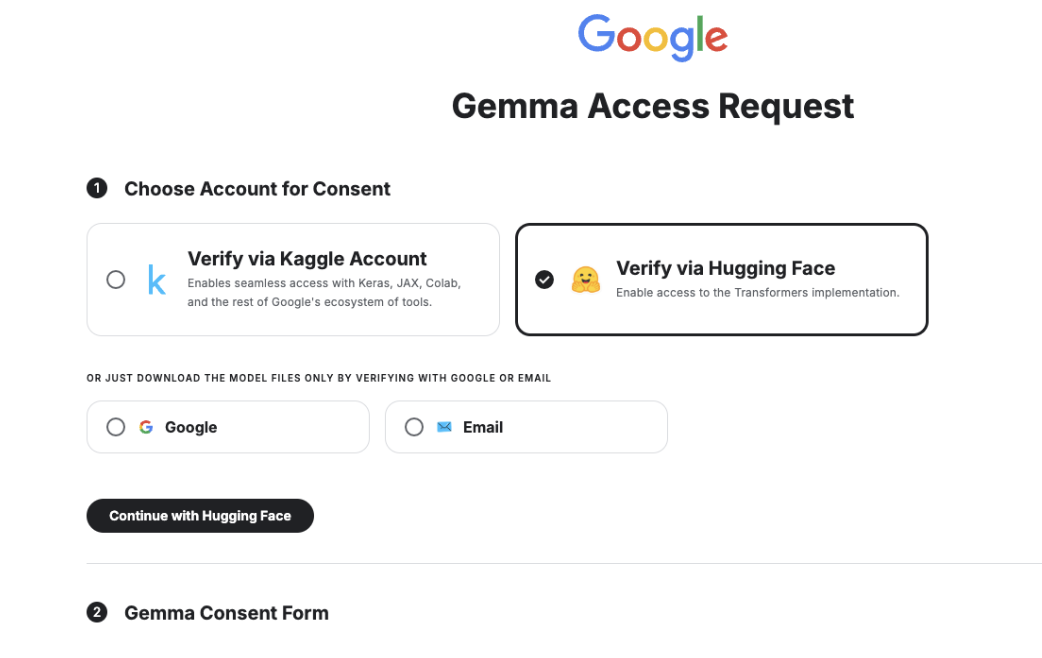
By following above step then will get as
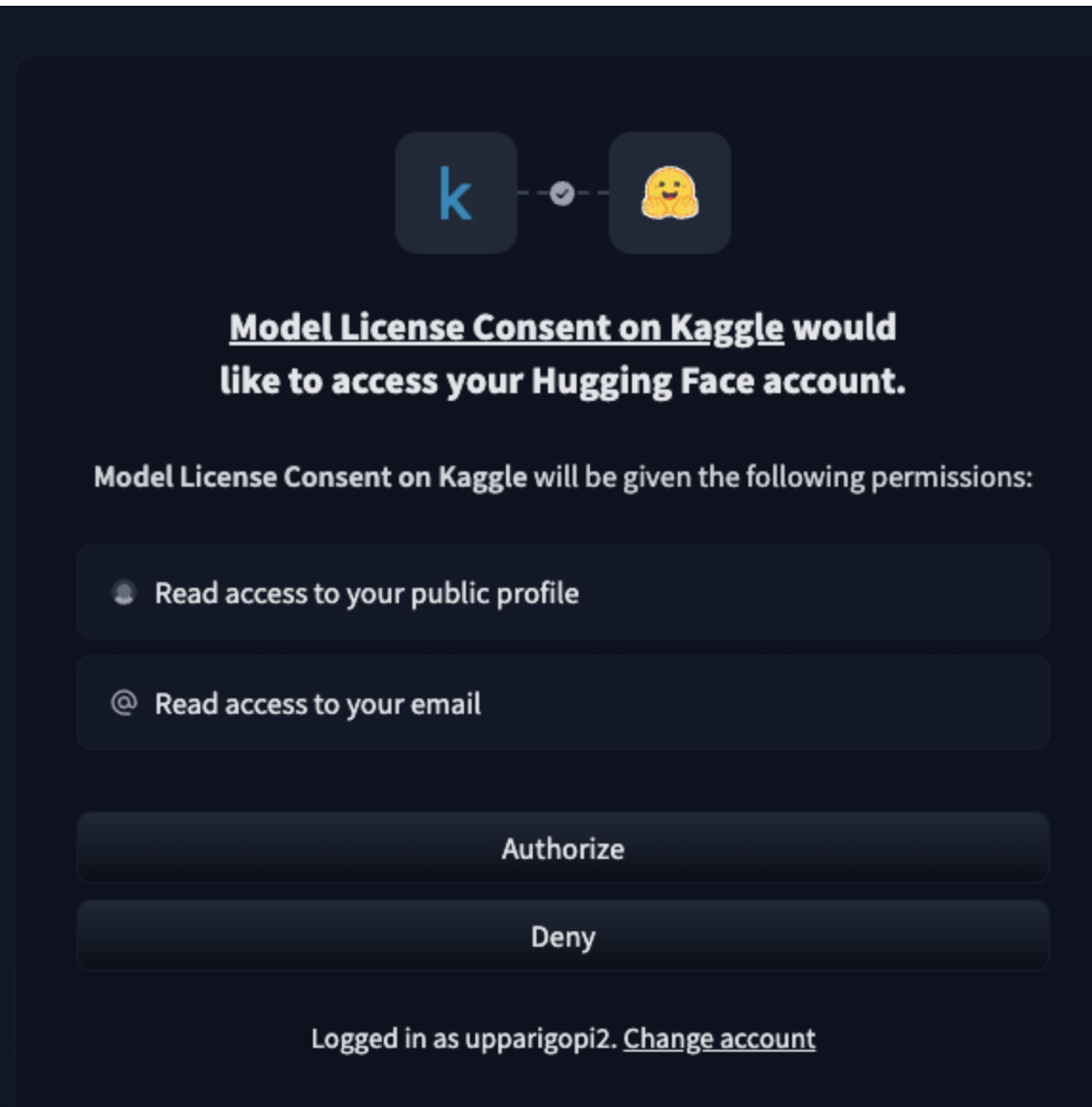
Click on "Authorize," which will redirect you to the Kaggle Gemma Consent Form page. Fill out the required fields, accept the terms, and you will receive access to the Google Gemma models on HuggingFace in less than a minute.
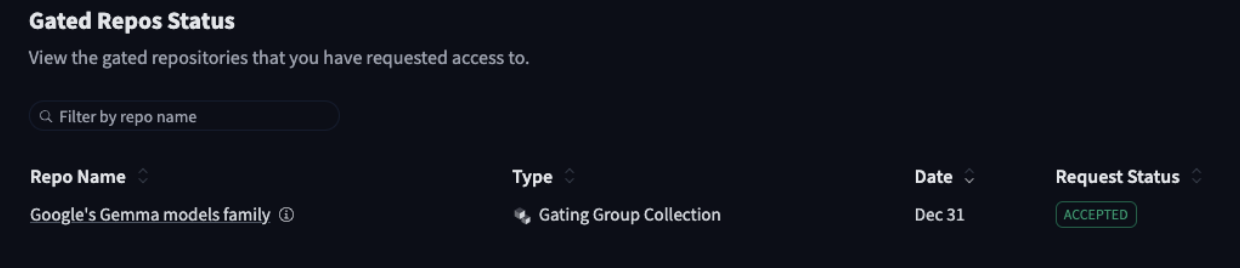
Thank you.
